Monday, May 01, 2000
“I know, let's make the same mistake!”
One of the mailing lists I'm on mentioned that the company that makes the Web Surfer made the same mistake as the Netpliance and neglected to make the purchase of the device conditional on the purchase of Internet service.
It's cheaper than the IOpener, but it lacks the LCD display that made the IOpener such a deal, but at US$50 it wasn't a bad deal.
So Mark, Kelly (who had taken the day off) and I (who consults so I don't have an office to go to per say) headed off to CompUSA to see if we could procure some WebSurfers.
The CompUSA near had no units left. We asked at the customer desk to check some other stores and we found another store that had eight units left. Half an hour and 20 miles later we arrived at the other CompUSA.
I wish I had checked Slashdot first, because it seems that the Internet service may or may not be enforced and it depends upon the store. The store we went to I think might have enforced the service. So we are WebSurfless.
“I've got the code. You've got the server. Let's make lots of money.”
Hanging out with Mark and Kelly we started discussing ways to make money on the web, or more specifically, with www.conman.org.
Mark and I are both programmers but with the upswell of the Open Source movement, it's getting hard to actually sell software. The only way to really make money in Open Source is service. Both Mark and I write software, and even make it available. But since we give the software away, how to we make money from it? Well, hire us to install, or adapt the code for your particular project. Sure, if you have the time or the expertise you don't have to hire us, but with a shortage of time or expertise, we're available.
Or by making this available I can become a well known webcelebrity and get asked for talks and seminars (yea, right).
But making money off a website isn't straightforward, nor easy. And I'm not expecting to make money (at least, directly) off this site. Indirectly, yes. But not directly.
Wednesday, May 01, 2002
Melancholy molasses coasting beneath the eye of God
I've been in a rather off mood lately. Not exactly depressed, but not really wanting to do anything either. Just existing really.
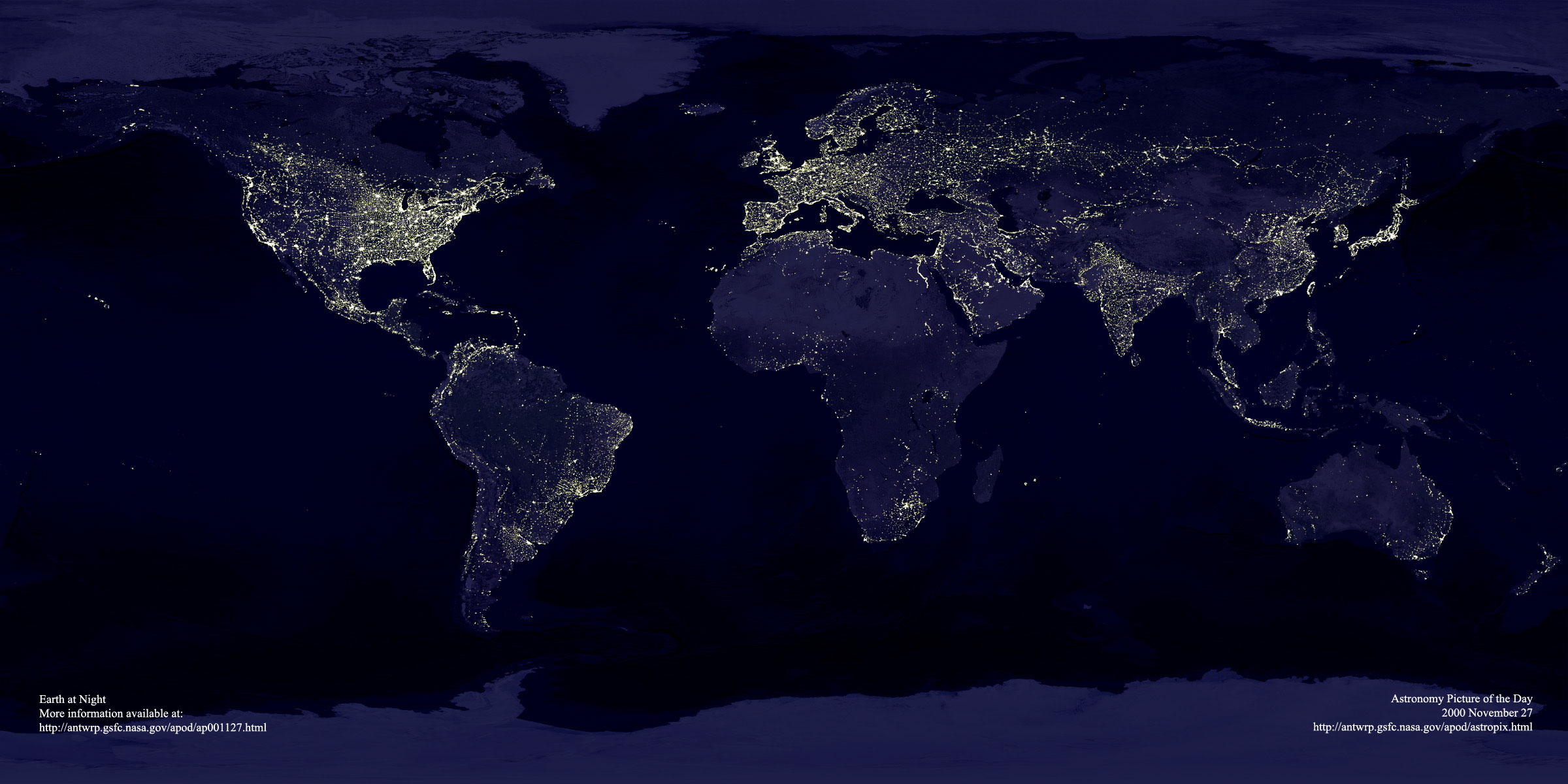 I came across a picture of Earth as taken at night and it has me both in awe and
depressed at the same time. Awe at the level of civilization we've
achieved. Here we are! A thousand points of light spread across the
face of the earth as we've changed the long dark night into day (or at least
twilight).
I came across a picture of Earth as taken at night and it has me both in awe and
depressed at the same time. Awe at the level of civilization we've
achieved. Here we are! A thousand points of light spread across the
face of the earth as we've changed the long dark night into day (or at least
twilight).
 And yet, depressed, for the very same reason. No longer can we
see the thousand points of light spreading across the sky. The stars have
fallen among us (and according to NORAD, tons of space debris are now poised
to rain down upon us as well) such that just by light alone, you can make out the continents upon
which we live. I'm also sad that stellar objects like the Hourglass Nebula may no longer be visible from the
ground (and when I first saw the high resolution image of that, I
immediately thought of Jerry Pournelle and Larry Niven's Mote in God's
Eye).
And yet, depressed, for the very same reason. No longer can we
see the thousand points of light spreading across the sky. The stars have
fallen among us (and according to NORAD, tons of space debris are now poised
to rain down upon us as well) such that just by light alone, you can make out the continents upon
which we live. I'm also sad that stellar objects like the Hourglass Nebula may no longer be visible from the
ground (and when I first saw the high resolution image of that, I
immediately thought of Jerry Pournelle and Larry Niven's Mote in God's
Eye).
I think though, that I've finally snapped out of whatever mood I've been in. And you've been warned—I've got quite a bit of backlog of entries to write, and some of them are quite technical in nature.
TCP Half-close mode and how it affects webserving
Over the past few days, Mark and I have been going over partial closures of a TCP connection, since under certain circumstances, you have to do that if you are writing a webserver, such as the one Mark is writing.
When a client or server wishes to time-out it SHOULD issue a graceful close on the transport connection. Clients and servers SHOULD both constantly watch for the other side of the transport close, and respond to it as appropriate. If a client or server does not detect the other side's close promptly it could cause unnecessary resource drain on the network.
§ 8.1.4 of RFC-2616
So far so good. But …
/* * More machine-dependent networking gooo... on some systems, * you've got to be *really* sure that all the packets are acknowledged * before closing the connection, since the client will not be able * to see the last response if their TCP buffer is flushed by a RST * packet from us, which is what the server's TCP stack will send * if it receives any request data after closing the connection. * * In an ideal world, this function would be accomplished by simply * setting the socket option SO_LINGER and handling it within the * server's TCP stack while the process continues on to the next request. * Unfortunately, it seems that most (if not all) operating systems * block the server process on close() when SO_LINGER is used. * For those that don't, see USE_SO_LINGER below. For the rest, * we have created a home-brew lingering_close. * * Many operating systems tend to block, puke, or otherwise mishandle * calls to shutdown only half of the connection. You should define * NO_LINGCLOSE in ap_config.h if such is the case for your system. */
Comment from http_main.c in the Apache source code.
And then …
Some users have observed no
FIN_WAIT_2problems with Apache 1.1.x, but with 1.2b enough connections build up in theFIN_WAIT_2state to crash their server. The most likely source for additionalFIN_WAIT_2states is a function calledlingering_close()which was added between 1.1 and 1.2. This function is necessary for the proper handling of persistent connections and any request which includes content in the message body (e.g.,PUTs andPOSTs). What it does is read any data sent by the client for a certain time after the server closes the connection. The exact reasons for doing this are somewhat complicated, but involve what happens if the client is making a request at the same time the server sends a response and closes the connection. Without lingering, the client might be forced to reset its TCP input buffer before it has a chance to read the server's response, and thus understand why the connection has closed. See the appendix for more details.The code in
lingering_close()appears to cause problems for a number of factors, including the change in traffic patterns that it causes. The code has been thoroughly reviewed and we are not aware of any bugs in it. It is possible that there is some problem in the BSD TCP stack, aside from the lack of a timeout for theFIN_WAIT_2state, exposed by thelingering_closecode that causes the observed problems.
Connections in
FIN_WAIT_2 and Apache
And the whole purpose of lingering_close() is to handle TCP half-closes when you
can't use the SO_LINGER option when creating the socket!
So Mark and I go back and forth a few times and I finally send Mark the following:
Okay, looking over Stevens (UNIX Network Programming [1990], TCP/IP Illustrated Volume 1 [1994], TCP/IP Illustrated Volume 2 [1995]) and the Apache source code, here's what is going on.
The TCP/IP stack itself (under UNIX, this happens in the kernel) is responsible for sending out the various packet types of
SYN,ACK,FIN,RST, etc. in response to what is done in user code. Ideally, for the server code, you would do (using the Berkeley sockets API since that's all the reference I have right now, and ignoring errors, which would only cloud the issue at hand):memset(&sin,0,sizeof(sin)); sin.sin_family = AF_INET; sin.sin_addr.s_addr = INADDR_ANY; sin.sin_port = htons(port); /* usually 80 for HTTP */ mastersock = socket(AF_INET,SOCK_STREAM,0); one = 1; setsockopt(mastersock,SOL_SOCKET,SO_REUSEADDR,&one,sizeof(one)); bind(mastersock,(struct sockaddr *)&sin,sizeof(sin)) while(...) { struct linger lingeropt; size_t length; int sock; int opt; listen(mastersock,5); length = sizeof(sin); sock = accept(sock,(struct sockaddr *)&sin,&length); opt = 1; lingeropt.l_onoff = 1; lingeropt.l_linger = SOME_TIME_OUT_IN_SECS; setsockopt(sock,IPPROTO_TCP,TCP_NODELAY,&opt,sizeof(opt)); setsockopt(sock,SOL_SOCKET,SO_LINGER,&li,sizeof(struct linger)); /*--------------------------------------------------- ; assuming HTTP/1.1, keep handling requests until ; a non-200 response it required, or the client ; sends a Connection: close or closes its side of the ; connection. When that happens, we can just close ; our side and everything is taken care of. ;----------------------------------------------------*/ close(sock); }There are two problems with this though that Apache attempts to deal with; 1)
close()blocks ifSO_LINGERis specified (not all TCP/IP stacks do this, just most it seems) and 2) TCP/IP stacks that have no timeout value in theFIN_WAIT_2state (which means sockets may be consumed if theFIN_WAIT_2states don't clear).Apache handles #2 by:
if ( TCP/IP stack has no timeout in FIN_WAIT_2 state) && ( client is a known client that can't handle persistent connections properly) then downgrade to HTTP/1.0. end(Apache will also downgrade to HTTP/1.0 for other browsers because they can't handle persistent connections properly anyway, and Apache will prevent them from crashing themselves, but I'm digressing here … )
Now, Apache handles #1 by rolling its own lingering close in userspace by writing any data it needs to the client, calling
shutdown(sock,SHUT_WR), setting timeouts (alarm(), timeout struct inselect(), etc) and reading any pending data from the client before issuing theclose()(and it never callssetsockopt(SO_LINGER)in this case). The reason Apache does this is because it needs to continue processing after theclose()and havingclose()block will affect the response time of Apache—that, and it seems some TCP/IP stacks can't handleSO_LINGERanyway and may crash (or seriously affect the throughput).So, if you don't mind
close()blocking (on a socket withSO_LINGER) and the TCP/IP stack won't puke or mishandle the socket, then the best bet would be to useSO_LINGER. Otherwise, you will have to do what Apache does and do something like:write(sock,pendingdata,sizeof(pendingdata)); shutdown(sock,SHUT_WR); alarm(SOME_TIME_OUT_IN_SECS); FD_ZERO(&fdlist); do { FD_SET(sock,&fdlist); tv.tv_sec = SOME_SMALLER_TIME_OUT_IN_SECS; tv.tv_usec = 0; rc = select(FD_SETSIZE,&fdlist,NULL,NULL,&tv); } while ((rc > 0) && (read(sock,dummybuf,sizeof(dummybuf)) > 0)); close(sock); alarm(0);(Apache has
SOME_TIME_OUT_IN_SECSequal to 30 andSOME_SMALLER_TIME_OUT_IN_SECSas 2).And in going over the Apache code more carefully, it does seem that Apache will use its own version of a lingering close for Linux. Heck, I can't see an OS that Apache supports that it actively uses
SO_LINGER(and I'm checking the latest version of 1.3).I'm not sure how you want to handle this, since the shutdown() call can close down either the read half, the write half (which is what the webserver needs to do in the case above) or both halves. The code you have for
HttpdSocket::Shutdown()should probably do somethine close to what I have above if you aren't usingSO_LINGER, and if you are usingSO_LINGER, then all it has to do is callclose().
That seems to have cleared up most of the misunderstandings we've been
having and now we're down to figuring out some minor details, as the
architecture Mark has chosen for his webserver make the possible blocking on
close() not that much of an issue and that more modern TCP/IP
stacks probably implement SO_LINGER correctly (or at least to the
degree that it doesn't puke or mishandle the option).
Indexing weblogs
I see that Nick Denton is launching a new venture that seems to be centered around marketing and weblog indexing; specifically, thoughts about weblog indexing.
I've talked about this a bit, but if a dedicated search engine wants to successfully scan a weblog there are a few ways to go about it.
One, grab the RSS file for the weblog and index the links from that. That will allow you to populate the search engine with the permanent links for the entries. Another thing it will allow you to do is properly index the appropriate entries. Google does a good job of indexing pages, but a rather poor one of indexing individual entries of a weblog, since it generally views pages as one entity and not as a possible collection of entities. So that if I mention say, “hot dogs” on the first of the month, “wet papertowels” on the fifteenth and “ugly gargoyles at Notre Dame” on the last day of the month, someone looking for “hot wet gargoyles” at Google is going to find the page that archives that month.
Which is probably not what I, nor the searcher in question, want.
Well, unless I'm looking for disturbing search request material, but I digress.
Even if the permanent links point to a portion of a page, the link would be something like
http://www.example.net/200204-index.html#31415926
Which points to a part of the page at
http://www.example.net/200204-index.html
And somewhere on that page is an anchor tag with the ID of “31415926” which is most likely at the top of the entry in question. From there you index until you hit the next named anchor tag that matches another entry in the RSS file.
And if you hit a site like mine, the RSS file will have links that bring up individual pages for each entry.
Now, you might still have to contend with a weblog that doesn't have an Rich Site Summary file, but then, you could just fall back to indexing between named anchor points anyway and use heuristics to figure out what may be the permanent links to index under.
I'm sure that people looking for “hot wet gargoyles” will thank you.
And finally, I reply back
And after twelve days, I finally reply back to MachFind's response to my initial query on becoming a member of their Creative Team of Experts.
I hope I gave them what they wanted.
A clarification on an interesting point
A friend of mine wrote in, having read what I wrote about DNS and asked for some clarifications. And yes, rereading what I wrote, I should probably pass on what I wrote back.
If someone typed this into their web browser:
http://www.example.com
… would they be redirected to:
http://www1.example.com:8080
????
I've never seen this work so I'm curious if that's how this is resolved by the nameserver.
It doesn't quite work that way. Normally, given a URL
http://www.example.com/
a browser would extract out the host portion, and do a DNS A record lookup:
ip = dns_resolve(host,A_RR);and if a port wasn't specified, use port 80 as a default:
connection = net_connection(ip,TCP,80);Using the
SRVrecord (which, to my knowledge, isn't used by any web browser that I know of currently), the code would look something like (for now, ignoring the priority codes and multiple servers issues):srvinfo = dns_resolve("_http._tcp" + host,SRV_RR); ip = dns_resolve(srvinfo.host,A_RR); connection = net_connection(ip,TCP,servinfo.port);It's handled completely at the DNS level and no HTTP redirect is sent at all. Unfortuately, nothing much (except for some Microsoft products, and Kerberos installations oddly enough) use the
SRVrecords, which means …PS: I have 2 never-used-domains (XXXXXXXXXXXX and XXXXXXXXXXXXXXXX) that I'd like to point to my home unix box. Unfortunately, XXXXXXXX blocks all port 80 traffic … I'm on the hunt for a free dynamic DNS provider that will handle port forwarding or give me the ability to edit the DNS records manually … with the end result being that I want all traffic for these two domains to reach my home machine.
You can't use them for this. Sorry.
You can add the records if you want (I have) but don't expect anything to use them anytime soon.
Saturday, May 01, 2004
The severe lack of connectivity
Yet more Internet outtages this week. Intermittent access late this week, with a complete outtage all day yesterday. In fact, over the past few weeks the connection here at the Facility in the Middle of Nowhere has been progressively getting worse. To the point that Spring order DSL. Once it gets here and works, we dropping cable (and most likely the TV side as well—the only ones that watch any significant amount of it are The Kids, and I can live without Good Eats (I'll miss it, but I can live without it).
I'm not sure what happened though—the cable Internet was rock solid when we first signed up.
Sigh.
An electronic archeological dig
An essay by Mark
Pilgrim on the history
of the tilde got me interested in figuring out when I first put up my
homepage, http://pineal.math.fau.edu/~spc/ (don't even bother
trying to go there—it's long dead link; I don't even think
pineal.math.fau.edu exists anymore). I still have a copy of
that site, but the earliest timestamp in that site is 1995, and I know I had
it prior to that. I think I used the NCSA server, which means I could have had the page up as early as
the summer of 1993, but 1994 sounds right to me.
A bit of digging in the archives reveals this email message I sent:
From: spc@pineal.math.fau.edu (Sean 'Captain Napalm' Conner)
To: XXXXXXXXXXXX (Hanh Vu)
Subject: Re: Lunch …
Date: Thu, 10 Nov 94 16:16:42 EST
A long long time ago in a network far far away, The Great Hanh Vu wrote:
-spc (Installing httpd on pineal … yup … I … broke down I'm gonna have a home page … )
Et tu, Sean …
Yea, well … you know … gotta keep up with the times …
-spc (but you can check out what I have with http://pineal.math.fau.edu/~spc/ … )
The surprising thing is that it was late 1994, not early 1994. Slap some CSS on the pages, and it wouldn't look half bad these days. I also found the following gem (which wasn't carried over to the current site):
The Atlantic Sun was the FAU school newspaper for many many years, from the mid 60's (when the university was founded) to about 1990. At this time, the paper was completely student run (there was not facaulty or staff supervisors).
In that year, the paper was very critical of the Administration (so what else is new). In order to strike back, the Administration looked at the academic records of each of the editors and found that most of them technically could not work for the newspaper with such abysmal GPAs. The editors of the newspaper where outraged and shouts of “Censorship” were heard about the campus.
In a very bold move, the newspaper persuaded the Student Goverment to give them several thousand dollars (on the order of about US$50,000), plus all the existing equipment to form a newspaper off campus and become completely independant. So, the old staff left campus with mucho dollars and all the equipment and set up shop about a mile off campus, and thumbed their noses at the Administration (as well as various other body parts).
One year later the Independant Atlantic Sun (as it was called) went bankrupt and folded operations.
It only took about three years for a new student newspaper to form.
Ah, politics. Ya gotta love it … (don't even ask about the Student Goverment here … )
If I remember correctly, the Student President and Student Senate Speaker had resigned due to rumors of suspicious activities, and the quickly held elections were declared invalid by the Student Judicial Branch. That caused the Student Senate to start impeachment proceedings against all the Student Justices. Had everything gone down, the Student council would have consisted of a Vice President (as acting President), three Senators (whose positions were not up for re-election) and no Judicial Branch. It didn't end up that way, but such was the politics of FAU in 1995.
But I digress …
Oh, and yes, I do have email going back that far, possibly a bit further in the past—hard to say when exactly I started saving all my outgoing email. Why I remember—self preservation. A friend of mine was having problems with one of the facaulty and felt it best to keep a copy of all correspondence, just in case. So I started doing the same as well.
And this whole pile of textual bits is courteously of ever increasing densities of harddrives (link via 0xDECAFEBAD).
Monday, May 01, 2006
Oh, so that WAS the problem
The problem wasn't with OSPF—it was with the port settings.
Sigh.
I keep forgetting that on Cisco routers, interfaces named “Ethernet” are only 10Mbps, while “FastEthernet” are 100Mbps. Also, 10Mbps interfaces are not full duplex, but half duplex.
Now that I've made those changes, the problem seems to have gone away.
I have to remember: Ethernet are 10Mbps, FastEthernet are 100Mbps.
“I promise—THIS is a webkiller!”
- From
- "Its Here" <XXXXXXXXXXXXXXXXXXXXXXX>
- To
- sean@conman.org
- Subject
- Web Killer
- Date
- 01 May 2006 12:38:34 -0500
Web Killer is the code name for V2, a new technology that will eventually replace the World Wide Web. We finely have a technology to take us to the next level of online computing.Find out where its going, what it means for you and how you can be apart of the journey. (www.OsiXs.org)
Welcome to the First Phase …
There isn't much to the site that actually describes what V2 is, or does, or how it accomplishes or wishes to accomplish what it wants done, or much of anything other than “Hey! The Internet as you know it is dead! And we're the ones that are going to replace it with our cool technology! Please donate!”
Believe are not, you are witnessing history in the making. Write here and write now we are preparing to launch a totally new online world apart from the World Wide Web.
From OsiXs.org and what you see is exactly what appeared on the website.
There's even less here than at the website of the fastest proprietary 80x86 based operating system (at least at the time, you got something that booted), and from the looks of things, V2_OS (I doubt there's a relation between the two, but you never know) it failed to take the Internet by storm (in the seven years since I first linked to it).
They have some lofty goals (“It will eventually cut your taxes
because government will be streamlined and a lot more efficient in utilizing
and administering its resources.”
) but until I see something more
substantial (“show me something!”) I personally don't see this
going anywhere fast.
The Google Conspriacy A-go-go (for lack of a better title)
The more I read this site that's critical of Google, the less I understand what the heck Google is trying to do (and yes, I realize the site in question is heavily biased against Google, but unlike some other sites, this one doesn't come across like a conspriacy laden crack pot).
I always thought that Google made their money selling intranet (read: large private networks) search appliances and that the IPO was a legal requirement due to their number of outstanding shares. But from their recent filing (link via this page) they're no longer making the money they once were—perhaps they saturated the intranet search market?
I just don't understand what's going on inside Google.
Anyways, I decided to check how the Google AdSense is doing, and lo! I've made some money! I'm now up to stratospheric $8.19! I can afford lunch! Woot! I'm guessing some of the changes I've made behind the scenes have actually worked (basically, adding <!-- google_ad_section_start --> and <!-- google_ad_section_end --> around the actual content) so the Google Ads get to stay for the moment.
I also checked Amazon and while I'm doing way better with them, it's actually less money than I made in the same amount of time last year—I think the “mad money” I made with Amazon had more to do with timing than anything else.
One of the few bands that I'll bother to see in concert
I don't care for concerts and I've only been to a handfull in my life (well, excluding the ones I worked when I worked for the FAU auditorium stage crew) but there are a few bands (half a dozen) that I might make an exception and actually attend a concert.
I'm not sure what I dislike about concerts—the crowds of people, the huge venues (although I've only been to once arena concert—the rest have been at clubs) or the opening acts (none of the opening acts I've seen have been worth it—in fact, for once concert there were two opening acts; the first sucked, and the second one sucked loudly—fortunately the actual band we came for more than made up for the horrible opening acts) or the fact that concerts never start at the time printed upon the ticket.
And last night, there was an hour wait (tickets said 7:00 pm, things didn't start until 8:00 pm) and the opening act was … eh. Half the friends I went with found the opening act (forgot his name, but he played a ukelele and most of the songs seemed to have the same melody but different lyrics) and the other half hated the guy. Mercifully he only played for half an hour.
Half an hour later—
—took to the stage.
Woot!
![[They Might Be Giants, but they seem much bigger to me]](/2006/05/01/tmbg.jpg "They Might Be Giants, but they seem much bigger to me")
![[Confetti, shot during the song James K. Polk]](/2006/05/01/jamespolk.jpg "Confetti, shot during the song James K. Polk")
You'll have to excuse the pictures—those are the best ones that my cell phone took during the concert.
It's been awhile since I last saw them in concert—90? 91? 92?—back then it was just the Johns. This time it was the Johns and the Dans (although the drummer wasn't a Dan, oddly enough). And since it's been awhile, about half the material was new to me, which was nice.
But oddly enough, of what I consider their “signature” songs, Particle Man, Instanbul (was once Contantinople) and Birdhouse in your Soul, they didn't play Particle Man. Minor nit-pick though.
And they were certainly worth the horror of the ukelele playing opening act.
Tuesday, May 01, 2007
09 F9 11 02 9D 74 E3 5B D8 41 56 C5 63 56 88 C0
It took the computer industry over a decade and millions of dollars to realize that copy protection just doesn't work. There are too many bored, intelligent and (more importantly) broke high school and college age kids who view copy protection as a game, an intellectual diversion, and will work hours, nay, days to crack a sceme.
It's just sad that the entertainment industry has to learn the same expensive lession over a similar time period.
Which version was I using again?
Sorry if you've signed up for email notification and gotten some wierd notifications over the past twelve hours. That's because there was a show-stopping bug in the code that only now was triggered.
You see, I rewrote the email notification code some time ago, but hadn't fully tested it yet. Then, a few days ago I decided to add in custom error pages and kept having issues. I knew I had done it before, then I realized I did, over there, but the custom error pages weren't working over here. I thought maybe it was a different version of the code.
So I checked out a fresh copy over at the other place to see if I broke whatever it was that made the custom pages work (it was using an older code base there), and it still worked. But since I'm not using email notification over there, the new email notification code was still untested.
So I checked out a fresh copy here. The custom error pages were still broken.
Turns out it was the installation of Apache on the server here (I used the distro-installed version for a change)—seems that it has a directory alias for /error/, which just so happens is what I named the directory. Had I named it /errors/ (plural) things would have worked the first time and all of this wouldn't have happened (or rather, would have happened at a later time).
Sigh.
But I did.
But notice that I hadn't tested the email notification code yet.
Until yesterday and today.
And boy, did things blow up.
The program kept crashing. Normally, that isn't much of an issue (well, okay, it is an issue) because normally, one is in front of the program to watch it crash, but in this case, I wasn't aware of the crash, because I used the email interface.
Now, mod_blog takes the entry (from a web page, a file, or through email), adds it to the archive, generates the new page, and then, if enabled, sends the email notifications.
It was crashing (unbeknowst to me) during the email notifications.
Postfix has been instructed to send emails to a particular address to mod_blog, which it does. But Postfix also notices that the program crashed. So it requeues the email.
And when the program crashes, the update lock it has is released (technically, it's a file lock that the kernel maintains, but hey, the program goes away, so does the lock).
Next entry comes along, process repeats, and Postfix realizes it has some email queued up, and tries to send that at the same time. Now we have two processes trying to update the blog. Normally, this isn't an issue because of the update lock. But the lock is released in an uncontrolled state and …
Things blow up and get ugly.
But what I'm seeing is a blog that failed a validation check, I fix it, only to have it fail the validation check again, which I fix, only to fail the validation yet again, only now I notice that the same entry I thought I fixed twice keeps coming back to haunt me and even worse, the entire front page is a mess, and is remaining a mess no matter what I do.
I tracked the problem down, but I may have sent some spurious notifications in doing so. Once I realized it was the new email notification code (and man, how did I ever check that code in? Leaks memory like you wouldn't believe! Sheesh) I reverted to the old version, cleared out the mail queue and hopefully, got this situation under control.
Thursday, May 01, 2014
The laptop computer is not to be used as a serving tray.
- From
- The Office Manager of the Ft. Lauderdale Office of the Corporation
- To
- The Ft. Lauderdale Office of the Corporation
- Subject
- Seating Arrangements for Today 5/1
- Date
- Thu, May 01, 2014 10:11 -0500
Hello Everyone,
Just an FYI today in regards to seating arrangements; our space is limited, so I have made the following changes for today:
- XXXXXXX Seattle guests are set up/sitting in the Manhattan Conference Room
- The Apollo Conference Room is for meetings only, please check calendar for availability
- XXXXXXX Florida employees—please have lunch in the QA area or Sean Conner’s office, if the Apollo Conference Room is not free
- The Apollo Conference Room is reserved
I wouldn't mind so much, but I find the excessive levels of mastication distracting.
Friday, May 01, 2015
Living with being dead
Most of the patients here have been diagnosed with garden-variety neurological disorders: schizophrenia, dementia, psychosis, severe depression, or bipolarism. But the ones I am searching for are different. They suffer from an affliction even more puzzling: They believe that they are dead.
It’s a rare disorder called Cotard’s syndrome, which few understand. For patients who have it, their hearts beat and lungs pump, yet they deny their existence or functionality of their bodies, organs or brains. They think their self is detached.
Via Hacker News, Living With Being Dead — Matter — Medium
I would like to congratulate Sean Hoade on his Zombi epalooza interview, and what better way to do that than to link to an article about people who think they're dead. Does that mean they think they're zombies? Or ghosts? Or just dead and their body has yet to notice?
Friday, May 01, 2020
It seems that C's bit-fields are more of a pessimization than an optimization
A few days ago, maybe a few weeks ago, I don't know, the days are all just merging together into one long undifferentiated timey wimey blob but I'm digress, I had the odd thought that maybe, perhaps, I could make my Motorola 6809 emulator faster by using a bit-field for the condition codes instead of the individual booleans I'm using now. The thought was to get rid of the somewhat expensive routines to convert the flags to a byte value and back. I haven't used bit-fields all that much in 30 years of C programming as they tend to be implementation dependent:
- Whether a “plain”
intbit-field is treated as asigned intbit-field or as anunsigned intbit-field (6.7.2, 6.7.2.1).- Allowable bit-field types other than
_Bool,signed int, andunsigned int(6.7.2.1).- Whether a bit-field can straddle a storage-unit boundary (6.7.2.1).
- The order of allocation of bit-fields within a unit (6.7.2.1).
- The alignment of non-bit-field members of structures (6.7.2.1). This should present no problem unless binary data written by one implementation is read by another.
- The integer type compatible with each enumerated type (6.7.2.2).
C99 standard, annex J.3.9
But I could at least see how gcc deals with them and see if there is indeed a performance increase.
I converted the definition of the condition codes from:
struct
{
bool e;
bool f;
bool h;
bool i;
bool n;
bool z;
bool v;
bool c;
} cc;
to
union
{
/*---------------------------------------------------
; I determined this ordering of the bits empirically.
;----------------------------------------------------*/
struct
{
bool c : 1;
bool v : 1;
bool z : 1;
bool n : 1;
bool i : 1;
bool h : 1;
bool f : 1;
bool e : 1;
} f;
mc6809byte__t b;
}
(Yes,
by using a union I'm inviting “unspecified behavior”—from the C99 standard: “[t]he value of a union member other than the last one stored into (6.2.6.1)”),
but at least gcc does the sane thing in this case.)
The code thus modified,
I ran some tests to see the speed up and the results were rather disappointing—it was slower using bit-fields than with 8 separate boolean values.
My guess is that the code used to set and check bits, especially in an expression like (cpu->cc.f.n == cpu->cc.f.v) && !cpu->cc.f.z was larger
(and thus slower)
than just using plain bool for each field.
So the upshot—by changing the code to use an implementation-defined detail and invoking unspecified behavior, thus making the resulting program less portable, I was able to slow the program down enough to see it wasn't worth the effort.
Perfect.
Saturday, May 01, 2021
What I did on my April vacation from the blog
It's been awhile since I last posted (never mind the previous posts—those were actually written today but pre-dated to earlier in the week because I'm lazy). Back in the last week of March, my hosting company changed data centers and because of “technical issues” the IP address my server has had for the past … um … 13 years? 15 years? A long time in any case, the IP address of my server has changed. I was a bit aprehensive about the change because of email (I'm going from a very clean IP address to an address of unknown provenance) and of course I had an email issue—but it wasn't with Gmail, oddly enough, but with Bunny's email provider (the Monopolistic Phone Company).
Sigh, here I am, unable to email a person that is 20 feet away from me! The horror!
All I got was that my IP address was on some realtime black list somewhere. Which one, I had no idea, because the Monopolistic Phone Company was mum on which list they use. I tried querying over 800 different black lists and only found one that listed my IP address—in Brazil! I find it odd that the Monopolistic Phone Company was using a realtime black list from Brazil, but hey, you never know.
It took a month, but now my emails get through the Monopolistic Phone Company's servers, and right into Bunny's junk folder. Progress!
There was also the DNS issues that took about a week to clear up. As part of the move, my hosting company's DNS servers were also changing IP addresses, and those had to be updated with the hosting company's registar which took some time to clear up.
But as of now, things seem to be back to normal around here.
An update on the Mt. Pfeiffer situation
Just in case anyone was interested in the Mt. Pfeiffer situation, I have to inform you that it had melted completely away by 8:45PM Eastern, March 18TH, with Aunt Betty TXXXXX winning the pool with a guess of 4:15PM Eastern.
I should note that I have no Aunt Betty and have no idea who she is. But hey, I'm happy she won the betting pool!
Extreme car alarm system, Delray Beach edition
In the parking lot of The Girls Strawberry U-Pick Ice Cream Shop and Animal Petting Farm (no, really! It's all that and more in the middle of some suburban sprawl—we went for the ice cream and were quite impressed) Bunny and I saw this angry pig in the windshield of a nearby parked car.
![[A toy stuffed pig in the windshield of a parked car, looking mighty angry] “Come on! Just a few steps closer! I dare ya! Just come another step closer …”](/2021/05/01/angry-pig.jpg "“Come on! Just a few steps closer! I dare ya! Just come another step closer …”")
I guess pigs are this year's trunk monkey.
Sunday, May 01, 2022
A zombie site from May Days past
Given that today is May Day I was curious as to what I wrote on past May Days.
And lo'
sixteen years ago I wrote about OsiXs.org and their attempt to “change the world!”
Amazingly,
the website is still around,
although with even less than there was sixteen years ago.
I guess I was right when I wrote back then,
“I personally don't see this going anywhere fast.”
It was a simple bug, but …
I was right about the double slash bug—it was a simple bug after all. The authors of two Gemini crawlers wrote in about the double slash bug, and from them, I was able to get the root cause of the problem—my blog on Gemini. Good thing I hedged my statement about not being the cause yesterday. Sigh.
Back in Debtember, I added support for displaying multiple posts. It's not an easy feature to describe, but basically, it allows one to (by hacking the URL, but who hacks URLs these days?) specify posts via a range of dates. And it's on these pages that the double slashed URLs appear. Why that happens is easy—I was generating the links directly from strings:
local function geminilink(entry)
return string.format("gemini://%s%s/%s%04d/%02d/%02d.%d",
config.url.host,
port, -- generated elsewhere
config.url.path,
entry.when.year,
entry.when.month,
entry.when.day,
entry.when.part
)
end
instead of from a URL type.
I think when I wrote the above code,
I wasn't thinking in terms of a URL type,
but of constructing a URL from data I already had.
The bug itself is due to config.url.path ending in a slash,
so the third slash in the string literal wasn't needed.
The correct way isn't that hard:
local function geminilink(entry)
return uurl.toa(uurl.merge(config.url,
{
path = string.format("%04d/%02d/%02d.%d",
entry.when.year,
entry.when.month,
entry.when.day,
entry.when.part)
}))
end
and it wouldn't have exhibited the issue.
With this fix in place, I think I will continue to reject requests with the double slash, as it is catching bugs, which is a Good Thing™.
Monday, May 01, 2023
The Case of the Inconsistent Consistent Chirp
Bunny and I were plagued with the most insidious inconsistently consistent chirp over the past few days here at Chez Boca. There would be this distinct chirp. Just one. And by the time you think it won't happen again, it would happen again. And then … nothing. For hours. Or maybe the rest of the day even. But sure enough, it would pick up again—a single chirp, then silence, then maybe another chirp, repeat for a few minutes then, nothing more for hours.
When it first started, I thought maybe one of the UPSes was responding to some power fluctuation, but no, they squeal quite loudly, and none of them showed any form of distress when I checked. This was more of a short chirp than a loud squeal. And by the time I was tired of looking at whatever UPS I thought it might be and turn away, there was another chirp.
It was mocking us.
Between the two of us, we had narrowed down the possible source in Chez Boca, somewhere along the west wall of the house. The only things in the area that could possible chirp were:
- a large vertical floor fan;
- a USP for the TV system;
- the TV itself;
- the DVR;
- the DVD player;
- the small network router for the DVR;
- a floor lamp.
But all these devices had been there for years before this chirping had started. It was weird as it was maddening.
I even went so far as to check the bathroom, as, from where I sit in the Computer Room, the chirp could be coming from there. The only three things in the bathroom that could possible chirp: the lights, Bunny's electric toothbrush and a small clock.
I discounted the lights—they're the original fixtures from the 70s—no strange electronics in there, and more importantly, no speakers to speak of. I did unplug the base unit of Bunny's electric toothbrush, and had the toothbrush itself in the Computer Room. The chirp didn't go away, and it wasn't from the toothbrush. Nor was it from the small electric clock (I too, brought that in to the Computer Room and cleared it as a suspect).
Then, late Saturday night, I was in the family room along with Bunny when it happened again. We were standing far enough apart that it appeared to be the floor lamp just by simple tiangulation. During an examination of the lamp, I happened to glance up, and there, above the door to the Computer Room, was a small, round disk shaped device stuck to the wall—a smoke detector.
Bingo!
Taking the unit down and reading the back, yes, it would chirp to indicate the battery needed changing. And neither Bunny nor I could recall when the battery in the unit was changed.
Heck, we both forgot about the unit being there at all.
Even worse, when I started telling this story to some friends at our regularly scheduled D&D game, they knew the punchline even before I finished. Sigh.
Now I just have to figure out why our ice maker is making hollow ice.

![[Self-portrait with my new glasses]](https://www.conman.org/people/spc/about/2025/0925.t.jpg "Glasses. Titanium, not steel.")
{kind=link}