Wednesday, May 01, 2002
Melancholy molasses coasting beneath the eye of God
I've been in a rather off mood lately. Not exactly depressed, but not really wanting to do anything either. Just existing really.
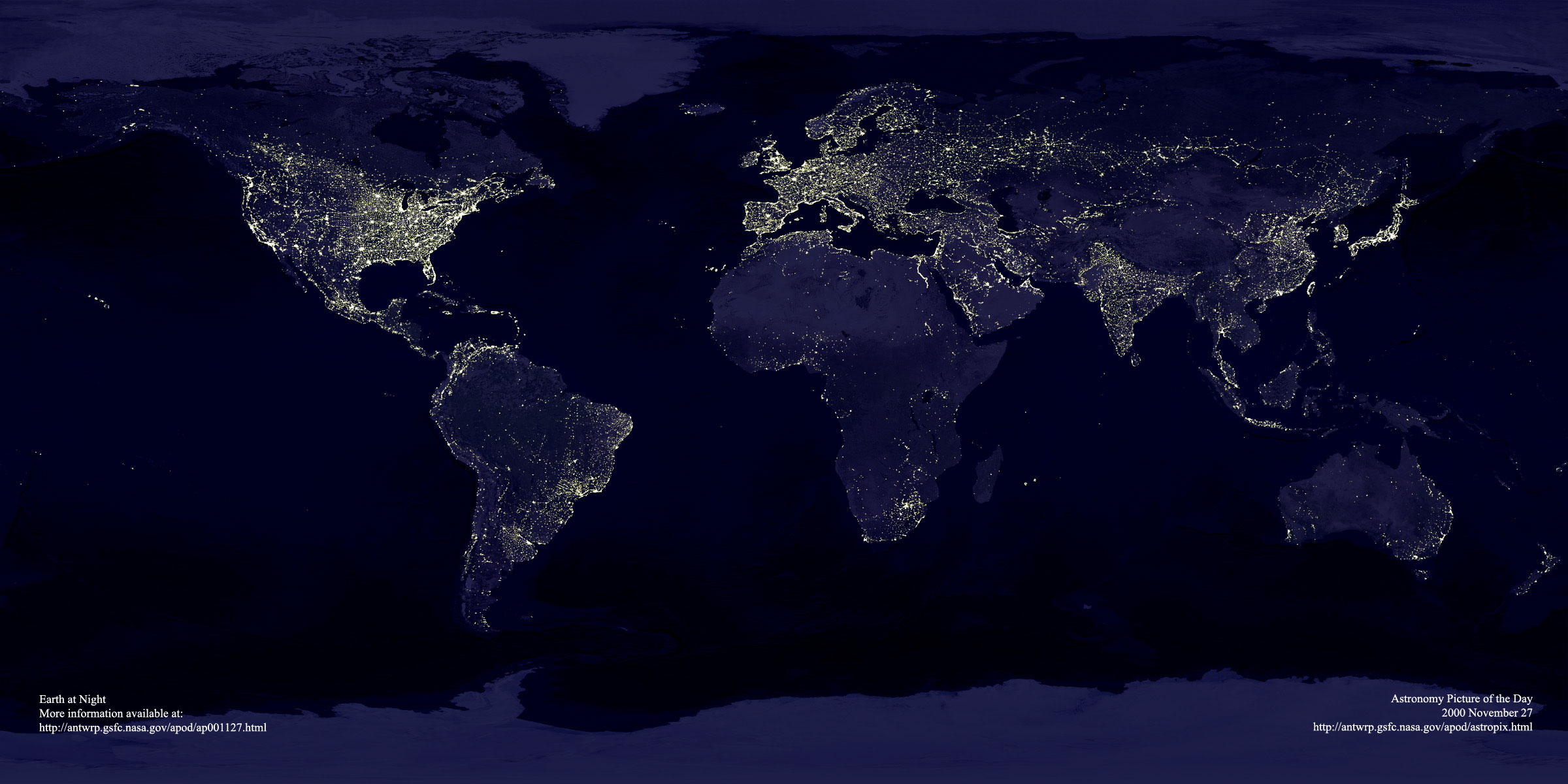 I came across a picture of Earth as taken at night and it has me both in awe and
depressed at the same time. Awe at the level of civilization we've
achieved. Here we are! A thousand points of light spread across the
face of the earth as we've changed the long dark night into day (or at least
twilight).
I came across a picture of Earth as taken at night and it has me both in awe and
depressed at the same time. Awe at the level of civilization we've
achieved. Here we are! A thousand points of light spread across the
face of the earth as we've changed the long dark night into day (or at least
twilight).
 And yet, depressed, for the very same reason. No longer can we
see the thousand points of light spreading across the sky. The stars have
fallen among us (and according to NORAD, tons of space debris are now poised
to rain down upon us as well) such that just by light alone, you can make out the continents upon
which we live. I'm also sad that stellar objects like the Hourglass Nebula may no longer be visible from the
ground (and when I first saw the high resolution image of that, I
immediately thought of Jerry Pournelle and Larry Niven's Mote in God's
Eye).
And yet, depressed, for the very same reason. No longer can we
see the thousand points of light spreading across the sky. The stars have
fallen among us (and according to NORAD, tons of space debris are now poised
to rain down upon us as well) such that just by light alone, you can make out the continents upon
which we live. I'm also sad that stellar objects like the Hourglass Nebula may no longer be visible from the
ground (and when I first saw the high resolution image of that, I
immediately thought of Jerry Pournelle and Larry Niven's Mote in God's
Eye).
I think though, that I've finally snapped out of whatever mood I've been in. And you've been warned—I've got quite a bit of backlog of entries to write, and some of them are quite technical in nature.
TCP Half-close mode and how it affects webserving
Over the past few days, Mark and I have been going over partial closures of a TCP connection, since under certain circumstances, you have to do that if you are writing a webserver, such as the one Mark is writing.
When a client or server wishes to time-out it SHOULD issue a graceful close on the transport connection. Clients and servers SHOULD both constantly watch for the other side of the transport close, and respond to it as appropriate. If a client or server does not detect the other side's close promptly it could cause unnecessary resource drain on the network.
§ 8.1.4 of RFC-2616
So far so good. But …
/* * More machine-dependent networking gooo... on some systems, * you've got to be *really* sure that all the packets are acknowledged * before closing the connection, since the client will not be able * to see the last response if their TCP buffer is flushed by a RST * packet from us, which is what the server's TCP stack will send * if it receives any request data after closing the connection. * * In an ideal world, this function would be accomplished by simply * setting the socket option SO_LINGER and handling it within the * server's TCP stack while the process continues on to the next request. * Unfortunately, it seems that most (if not all) operating systems * block the server process on close() when SO_LINGER is used. * For those that don't, see USE_SO_LINGER below. For the rest, * we have created a home-brew lingering_close. * * Many operating systems tend to block, puke, or otherwise mishandle * calls to shutdown only half of the connection. You should define * NO_LINGCLOSE in ap_config.h if such is the case for your system. */
Comment from http_main.c in the Apache source code.
And then …
Some users have observed no
FIN_WAIT_2problems with Apache 1.1.x, but with 1.2b enough connections build up in theFIN_WAIT_2state to crash their server. The most likely source for additionalFIN_WAIT_2states is a function calledlingering_close()which was added between 1.1 and 1.2. This function is necessary for the proper handling of persistent connections and any request which includes content in the message body (e.g.,PUTs andPOSTs). What it does is read any data sent by the client for a certain time after the server closes the connection. The exact reasons for doing this are somewhat complicated, but involve what happens if the client is making a request at the same time the server sends a response and closes the connection. Without lingering, the client might be forced to reset its TCP input buffer before it has a chance to read the server's response, and thus understand why the connection has closed. See the appendix for more details.The code in
lingering_close()appears to cause problems for a number of factors, including the change in traffic patterns that it causes. The code has been thoroughly reviewed and we are not aware of any bugs in it. It is possible that there is some problem in the BSD TCP stack, aside from the lack of a timeout for theFIN_WAIT_2state, exposed by thelingering_closecode that causes the observed problems.
Connections in
FIN_WAIT_2 and Apache
And the whole purpose of lingering_close() is to handle TCP half-closes when you
can't use the SO_LINGER option when creating the socket!
So Mark and I go back and forth a few times and I finally send Mark the following:
Okay, looking over Stevens (UNIX Network Programming [1990], TCP/IP Illustrated Volume 1 [1994], TCP/IP Illustrated Volume 2 [1995]) and the Apache source code, here's what is going on.
The TCP/IP stack itself (under UNIX, this happens in the kernel) is responsible for sending out the various packet types of
SYN,ACK,FIN,RST, etc. in response to what is done in user code. Ideally, for the server code, you would do (using the Berkeley sockets API since that's all the reference I have right now, and ignoring errors, which would only cloud the issue at hand):memset(&sin,0,sizeof(sin)); sin.sin_family = AF_INET; sin.sin_addr.s_addr = INADDR_ANY; sin.sin_port = htons(port); /* usually 80 for HTTP */ mastersock = socket(AF_INET,SOCK_STREAM,0); one = 1; setsockopt(mastersock,SOL_SOCKET,SO_REUSEADDR,&one,sizeof(one)); bind(mastersock,(struct sockaddr *)&sin,sizeof(sin)) while(...) { struct linger lingeropt; size_t length; int sock; int opt; listen(mastersock,5); length = sizeof(sin); sock = accept(sock,(struct sockaddr *)&sin,&length); opt = 1; lingeropt.l_onoff = 1; lingeropt.l_linger = SOME_TIME_OUT_IN_SECS; setsockopt(sock,IPPROTO_TCP,TCP_NODELAY,&opt,sizeof(opt)); setsockopt(sock,SOL_SOCKET,SO_LINGER,&li,sizeof(struct linger)); /*--------------------------------------------------- ; assuming HTTP/1.1, keep handling requests until ; a non-200 response it required, or the client ; sends a Connection: close or closes its side of the ; connection. When that happens, we can just close ; our side and everything is taken care of. ;----------------------------------------------------*/ close(sock); }There are two problems with this though that Apache attempts to deal with; 1)
close()blocks ifSO_LINGERis specified (not all TCP/IP stacks do this, just most it seems) and 2) TCP/IP stacks that have no timeout value in theFIN_WAIT_2state (which means sockets may be consumed if theFIN_WAIT_2states don't clear).Apache handles #2 by:
if ( TCP/IP stack has no timeout in FIN_WAIT_2 state) && ( client is a known client that can't handle persistent connections properly) then downgrade to HTTP/1.0. end(Apache will also downgrade to HTTP/1.0 for other browsers because they can't handle persistent connections properly anyway, and Apache will prevent them from crashing themselves, but I'm digressing here … )
Now, Apache handles #1 by rolling its own lingering close in userspace by writing any data it needs to the client, calling
shutdown(sock,SHUT_WR), setting timeouts (alarm(), timeout struct inselect(), etc) and reading any pending data from the client before issuing theclose()(and it never callssetsockopt(SO_LINGER)in this case). The reason Apache does this is because it needs to continue processing after theclose()and havingclose()block will affect the response time of Apache—that, and it seems some TCP/IP stacks can't handleSO_LINGERanyway and may crash (or seriously affect the throughput).So, if you don't mind
close()blocking (on a socket withSO_LINGER) and the TCP/IP stack won't puke or mishandle the socket, then the best bet would be to useSO_LINGER. Otherwise, you will have to do what Apache does and do something like:write(sock,pendingdata,sizeof(pendingdata)); shutdown(sock,SHUT_WR); alarm(SOME_TIME_OUT_IN_SECS); FD_ZERO(&fdlist); do { FD_SET(sock,&fdlist); tv.tv_sec = SOME_SMALLER_TIME_OUT_IN_SECS; tv.tv_usec = 0; rc = select(FD_SETSIZE,&fdlist,NULL,NULL,&tv); } while ((rc > 0) && (read(sock,dummybuf,sizeof(dummybuf)) > 0)); close(sock); alarm(0);(Apache has
SOME_TIME_OUT_IN_SECSequal to 30 andSOME_SMALLER_TIME_OUT_IN_SECSas 2).And in going over the Apache code more carefully, it does seem that Apache will use its own version of a lingering close for Linux. Heck, I can't see an OS that Apache supports that it actively uses
SO_LINGER(and I'm checking the latest version of 1.3).I'm not sure how you want to handle this, since the shutdown() call can close down either the read half, the write half (which is what the webserver needs to do in the case above) or both halves. The code you have for
HttpdSocket::Shutdown()should probably do somethine close to what I have above if you aren't usingSO_LINGER, and if you are usingSO_LINGER, then all it has to do is callclose().
That seems to have cleared up most of the misunderstandings we've been
having and now we're down to figuring out some minor details, as the
architecture Mark has chosen for his webserver make the possible blocking on
close() not that much of an issue and that more modern TCP/IP
stacks probably implement SO_LINGER correctly (or at least to the
degree that it doesn't puke or mishandle the option).
Indexing weblogs
I see that Nick Denton is launching a new venture that seems to be centered around marketing and weblog indexing; specifically, thoughts about weblog indexing.
I've talked about this a bit, but if a dedicated search engine wants to successfully scan a weblog there are a few ways to go about it.
One, grab the RSS file for the weblog and index the links from that. That will allow you to populate the search engine with the permanent links for the entries. Another thing it will allow you to do is properly index the appropriate entries. Google does a good job of indexing pages, but a rather poor one of indexing individual entries of a weblog, since it generally views pages as one entity and not as a possible collection of entities. So that if I mention say, “hot dogs” on the first of the month, “wet papertowels” on the fifteenth and “ugly gargoyles at Notre Dame” on the last day of the month, someone looking for “hot wet gargoyles” at Google is going to find the page that archives that month.
Which is probably not what I, nor the searcher in question, want.
Well, unless I'm looking for disturbing search request material, but I digress.
Even if the permanent links point to a portion of a page, the link would be something like
http://www.example.net/200204-index.html#31415926
Which points to a part of the page at
http://www.example.net/200204-index.html
And somewhere on that page is an anchor tag with the ID of “31415926” which is most likely at the top of the entry in question. From there you index until you hit the next named anchor tag that matches another entry in the RSS file.
And if you hit a site like mine, the RSS file will have links that bring up individual pages for each entry.
Now, you might still have to contend with a weblog that doesn't have an Rich Site Summary file, but then, you could just fall back to indexing between named anchor points anyway and use heuristics to figure out what may be the permanent links to index under.
I'm sure that people looking for “hot wet gargoyles” will thank you.
And finally, I reply back
And after twelve days, I finally reply back to MachFind's response to my initial query on becoming a member of their Creative Team of Experts.
I hope I gave them what they wanted.
A clarification on an interesting point
A friend of mine wrote in, having read what I wrote about DNS and asked for some clarifications. And yes, rereading what I wrote, I should probably pass on what I wrote back.
If someone typed this into their web browser:
http://www.example.com
… would they be redirected to:
http://www1.example.com:8080
????
I've never seen this work so I'm curious if that's how this is resolved by the nameserver.
It doesn't quite work that way. Normally, given a URL
http://www.example.com/
a browser would extract out the host portion, and do a DNS A record lookup:
ip = dns_resolve(host,A_RR);and if a port wasn't specified, use port 80 as a default:
connection = net_connection(ip,TCP,80);Using the
SRVrecord (which, to my knowledge, isn't used by any web browser that I know of currently), the code would look something like (for now, ignoring the priority codes and multiple servers issues):srvinfo = dns_resolve("_http._tcp" + host,SRV_RR); ip = dns_resolve(srvinfo.host,A_RR); connection = net_connection(ip,TCP,servinfo.port);It's handled completely at the DNS level and no HTTP redirect is sent at all. Unfortuately, nothing much (except for some Microsoft products, and Kerberos installations oddly enough) use the
SRVrecords, which means …PS: I have 2 never-used-domains (XXXXXXXXXXXX and XXXXXXXXXXXXXXXX) that I'd like to point to my home unix box. Unfortunately, XXXXXXXX blocks all port 80 traffic … I'm on the hunt for a free dynamic DNS provider that will handle port forwarding or give me the ability to edit the DNS records manually … with the end result being that I want all traffic for these two domains to reach my home machine.
You can't use them for this. Sorry.
You can add the records if you want (I have) but don't expect anything to use them anytime soon.

![[Self-portrait with my new glasses]](https://www.conman.org/people/spc/about/2025/0925.t.jpg "Glasses. Titanium, not steel.")
{kind=link}